Пишемо регулярні вирази, не знаючи регулярних виразів. Частина 2
- Частина 1.
- Частина 2
Застосовуємо регулярні вирази у Swift
Уявімо собі, що в нас є шматочок тексту відформатованого у вигляді Markdown, і ми хочемо витягнути з нього усі посилання. Звісно, ми можемо приєднати до проєкту яку-небудь бібліотеку з відкритим кодом, але якщо наш додаток не працює з Markdown на постійній основі, то навіщо тягнути величезну бібліотеку для єдиного, точкового застосування? В такому випадку цілком доречно замість неї використати вбудовані в iOS SDK регулярки, які ми застосуємо для того, щоб витягнути з тексту посилання у вигляді послідовності структур Link:
let someMarkdown = """
# Hello
This is markdown sample with
[Some link](https://www.some-link.com.ua)
Have *fun*!
"""
struct Link {
var title: String
var url: URL
}
let regexp = try NSRegularExpression(pattern: "?", options: [])
Спершу ми створимо регулярний вираз, що витягне з тексту всі посилання, при чому окремо посилання, і окремо їх відображення в тексті, а потім заповнимо цими значеннями структуру Link із відповідними полями. З такою структурою надалі буде досить зручно працювати у Swift.
Отже, вставляємо даний Markdown як тестовий рядок, і знову пишемо регулярку. Що таке посилання в Markdown? Це квадратні дужки, в них якийсь текст, далі круглі дужки, і в них теж якийсь текст:
[якийсь текст](якийсь текст)
Якийсь текст - це .*, тобто “будь-який символ будь-яку кількість разів”. Так і запишемо, пам’ятаючи, що круглі та квадратні дужки є операторами в регулярних виразах, тому їх потрібно екранувати:
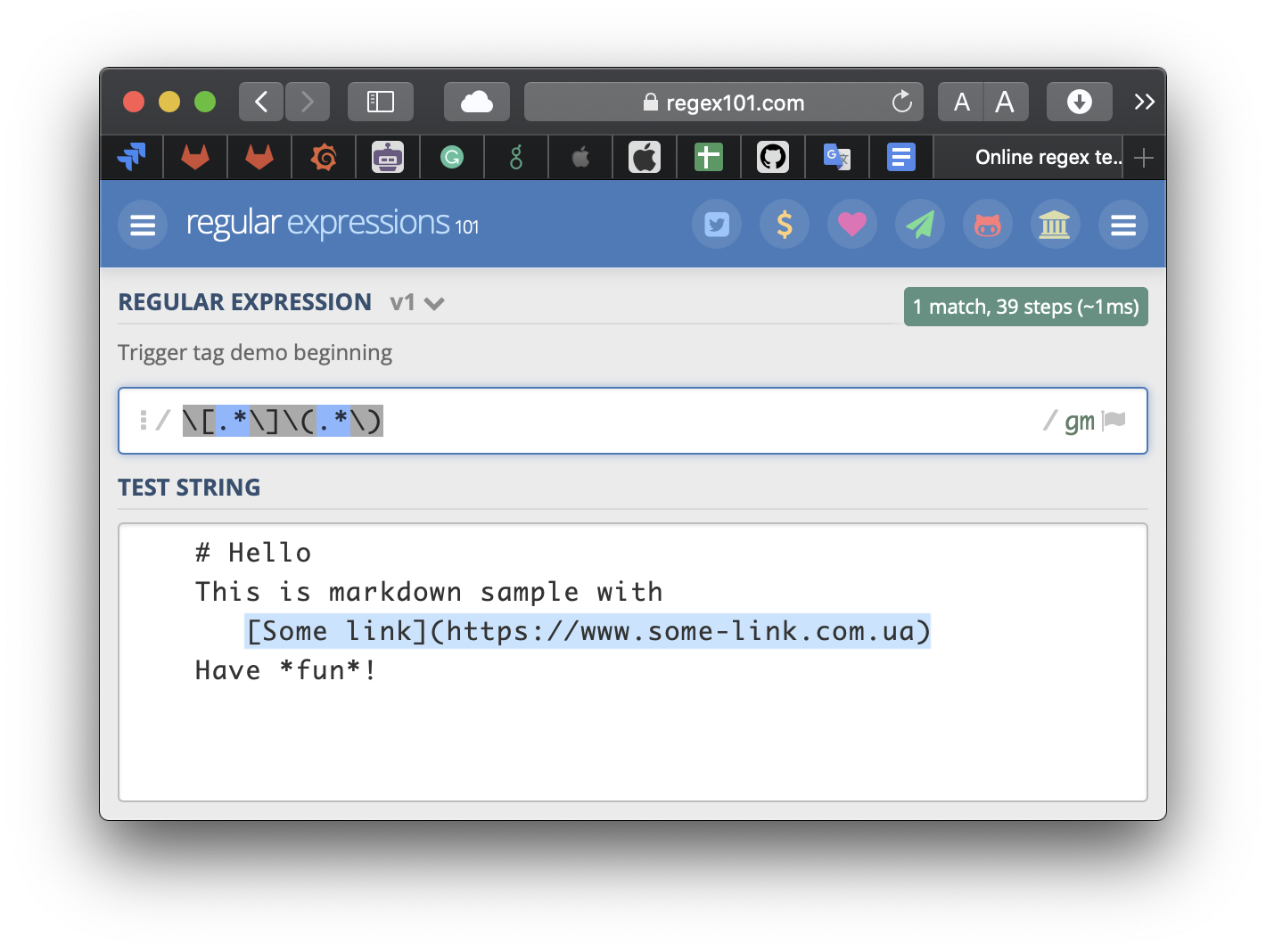
Ура, у нас є співпадіння! Однак, нам треба не лише співпадіння, нам треба якось заодно від цього співпадіння відгризти власне, назву посилання та саме посилання. Для цього в регулярних виразах є оператори групування, що записуються у вигляді круглих дужок. Просто беремо речі, які нам треба отримати окремо від співпадіння, і обводимо їх круглими дужками:
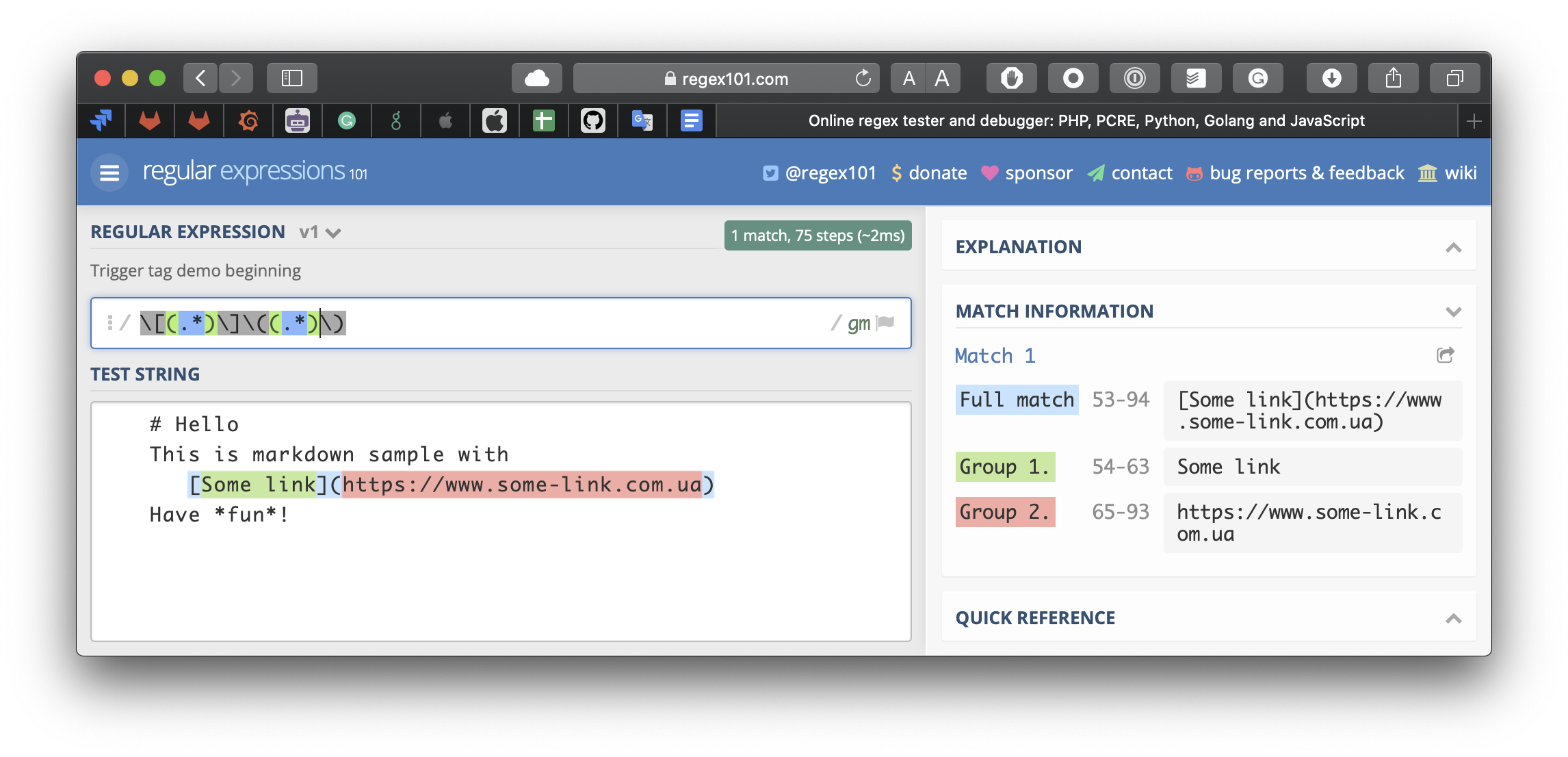
Справа посередині, у секції “Match Information”, бачимо, що окрім співпадіння, регулярний вираз виокремлює окремо назву посилання (Group 1), і окремо текст посилання (Group 2). Тепер можемо використати цю регулярку у Swift. Парсити структури Link із тексту ми будемо в розширенні самої структури Link, для зручності:
extension Link {
static func parse(markdown: String) -> [Link] {
// Крок 1: Створюємо регулярний вираз
let regexp = try! NSRegularExpression(
pattern: "\\[(.*)\\]\\((.*)\\)",
options: []
)
}
}
Слід зауважити, що коли в рядковому літералі у Swift є бек слеш, компілятор Swift його інтерпретує по-своєму на етапі компіляції, тому для того, щоб бек слеш дожив до часу виконання, коли буде створюватись регулярний вираз, його потрібно екранувати ще одним бек слешем. Тому вираз \[(.*)\]\((.*)\) перетворюється на більш громіздкий вираз \\[(.*)\\]\\((.*)\\). Однак, якщо в майбутньому ми захочемо змінити цей регулярний вираз, нам доведеться копіювати його до regex101.com, прибирати бек слеші, потім вставляти його назад в Xcode, додавати бек слеші, а там і помилитись нескладно. На щастя, у Swift 5 було реалізовано пропозицію SE-0200, котра дозволяє не екранувати бек слеші бек слешами, якщо рядок оточено ґратами:
extension Link {
static func parse(markdown: String) -> [Link] {
// Крок 1: Створюємо регулярний вираз
let regexp = try! NSRegularExpression(
pattern: #"\[(.*)\]\((\S+)\)"#,
options: []
)
}
}
Фактично, парсинг тексту зводиться до того, щоб застосувати регулярку до тексту, та кожному її співпадінню поставити у відповідність екземпляр структури Link:
extension Link {
static func parse(markdown: String) -> [Link] {
// Крок 1: Створюємо регулярний вираз
let regexp = try! NSRegularExpression(
pattern: #"\[(.*)\]\((\S+)\)"#,
options: []
)
// Крок 2: Отримуємо співпадіння
let matches = regexp.matches(
in: markdown, options: [],
range: NSRange(location: 0, length: markdown.count)
)
// Крок 3: Кожному співпадінню ставимо у відповідність екземпляр структури Link
return matches.compactMap { match in
return Link(markdown: markdown, match: match)
}
}
}
extension Link {
init?(markdown: String, match: NSTextCheckingResult) {
// ...
}
}
Для цього ми створимо спеціальний ініціалізатор, що приймає у якості параметрів сам текст, та екземпляр класу NSTextCheckingResult. Давайте з’ясуємо, як отримати з NSTextCheckingResult назву та текст посилання?
Клас NSTextCheckingResult має цікаву властивість numberOfRanges, яка зберігає кількість груп у співпадінні плюс саме співпадіння, та метод range(at idx: Int) -> NSRange, що повертає діапазон символів у вихідному тексті, що відповідає співпадінню або групі. Таким чином, match.range(at: 0) поверне саме співпадіння, match.range(at: 1) – групу 1, що містить назву посилання, а match.range(at: 2) – групу 2, що містить текст посилання.
| Regexp | NSTextCheckingResult |
|---|---|
[Some link](https://www.link.com.ua) | match.numberOfRanges == 3 |
Full Match: 0-36[Some link](https://www.link.com.ua) | // NSRange(0, 36)match.range(at: 0) |
Group 1: 1-10Some link | // NSRange(1, 10)match.range(at: 1) |
Group 2: 12-35https://www.link.com.ua | // NSRange(12, 35)match.range(at: 2) |
Таким чином ми можемо створити потрібний нам ініціалізатор:
extension Link {
init?(markdown: String, match: NSTextCheckingResult) {
// Крок 1: отримуємо дані, як підрядки початковго тексту.
guard
match.numberOfRanges == 3,
let titleString = markdown.substring(nsRange: match.range(at: 1)),
let urlString = markdown.substring(nsRange: match.range(at: 2))
else {
return nil
}
// Крок 2: валідуємо дані. Ми могли би описати валідацію URL в регулярках, але навіщо:
// при створенні URL з рядка все одно відбувається валідація.
guard let url = URL(string: String(urlString)) else { return nil }
// Крок 3: Звичайна ініціалізація властивостей структури.
self.title = String(titleString)
self.url = url
}
}
Звісно, даний код не працюватиме, якщо не реалізувати допоміжний метод в розширенні String:
extension String {
func substring(nsRange: NSRange) -> Substring? {
guard let range = Range(nsRange, in: self) else { return nil }
return self[range]
}
}
Як бачимо, завдяки використанню регулярного виразу, парсити складні речі у тексті стає просто, а головне, код мовою Swift при цьому є простим, лінійним та зрозумілим. Однак, його все ще можна покращити.
Пакращення вже сягодні
Що мені не подобається в цьому коді, так це ось ці рядки:
let titleString = markdown.substring(nsRange: match.range(at: 1)),
let urlString = markdown.substring(nsRange: match.range(at: 2))
Ми тут номерам 1 та 2 ставимо у відповідність titleString та urlString, і ця відповідність неочевидна. Звісно, формат Markdown навряд чи завтра зміниться, тому ця відповідність є стабільною, однак у загальному випадку такі відповідності є ознакою ненадійного коду, що може з часом перестати працювати.
На наше щастя, групи у регулярних виразах бувають іменованими. Нехай у нас є якась група (some expression), її можна поіменувати одним із двох способів: (?'name'some expression) або (?<name>some expression). Якщо ми поіменуємо групи в regex101.com, то побачимо в Match Information, що групи тепер не нумеруються, а іменуються.
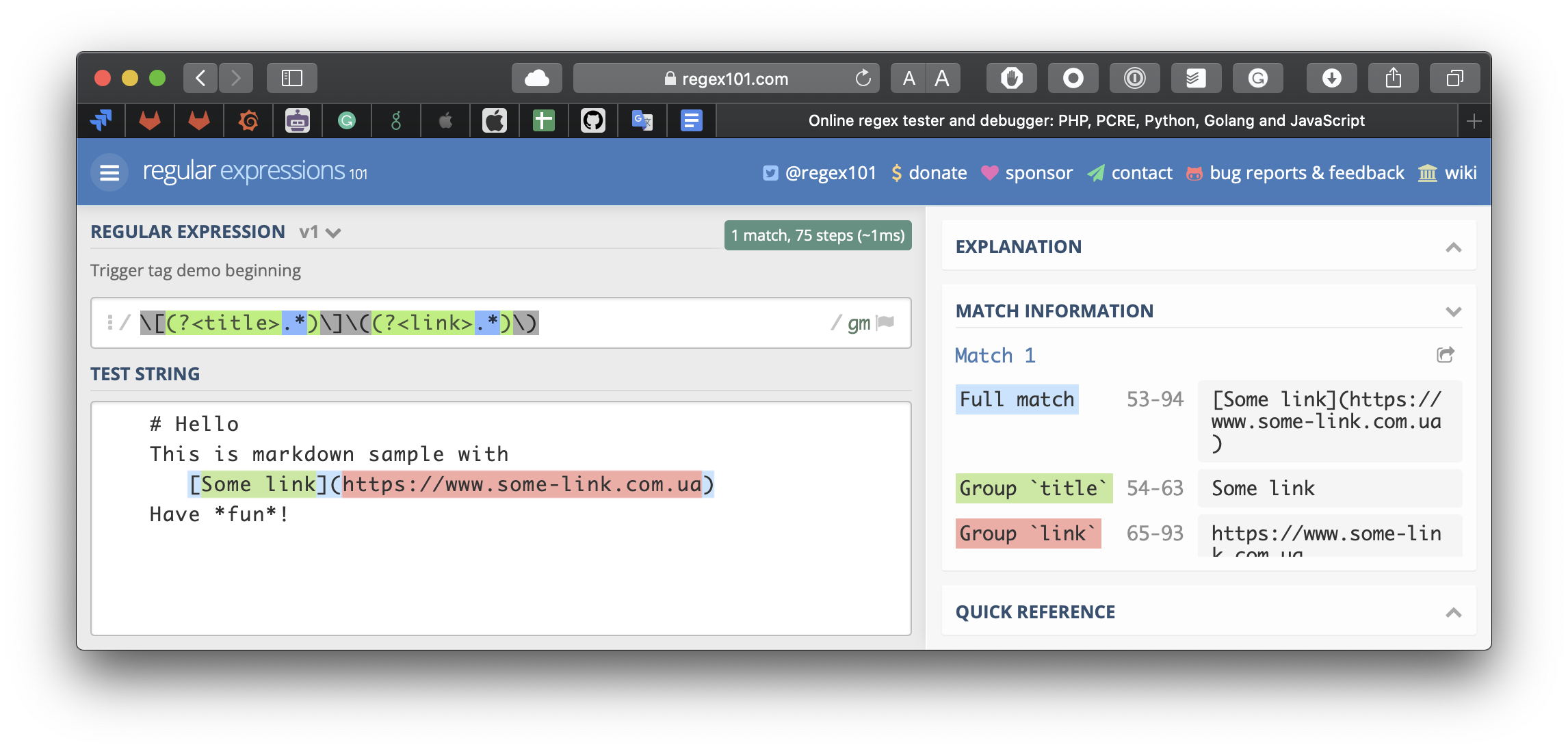
Тепер ми можемо витягнути текст з певної групи не за номером, а за іменем групи:
| Regexp | NSTextCheckingResult |
|---|---|
[Some link](https://www.link.com.ua) | match.numberOfRanges == 3 |
Full Match: 0-36[Some link](https://www.link.com.ua) | // NSRange(0, 36)match.range(at: 0) |
Group 'title': 1-10Some link | // NSRange(1, 10)match.range(withName: "title") |
Group 'link': 12-35https://www.link.com.ua | // NSRange(12, 35)match.range(withName: "link") |
Тому можна записати наш ініціалізатор структури Link у зрозумілішій та стабільнішій формі:
extension Link {
init?(markdown: String, match: NSTextCheckingResult) {
// Крок 1: отримуємо дані, як підрядки початковго тексту.
guard
let titleString = markdown.substring(nsRange: match.range(withName: "title")),
let urlString = markdown.substring(nsRange: match.range(withName: "link"))
else {
return nil
}
// Крок 2: валідуємо дані.
guard let url = URL(string: urlString) else { return nil }
// Крок 3: Звичайна ініціалізація властивостей структури.
self.title = titleString
self.url = url
}
}
Звісно, рядки "title" та "link" варто винести у константи, але я вірю в те, що ви й самі це точно вмієте.
Як ще можна покращити цей код? Ну, якщо ми повернемось до методу parse(markdown:), то помітимо, що регулярний вираз створюється прямо в ньому. Це іноді зручно, але не варто забувати, що регулярні вирази – це окрема мова, а їх створення – це по суті компіляція коду якоюсь мовою, що відбувається під час виконання вашої програми. Всі, хто мали справу з компіляцією коду мовою Swift, знають, що компіляція – це не найдешевша операція, тому нема чого її виконувати щоразу при спробі розпарсити тест. Варто виносити регулярні вирази у статичні константи: так вони будуть створюватись ліниво і лише один раз за все життя вашого додатку:
extension Link {
// Крок 1: Створюємо регулярний вираз
private static let regexp = try! NSRegularExpression(
pattern: #"\[(?<title>.*)\]\((?<url>\S+)\)"#,
options: []
)
static func parse(markdown: String) -> [Link] {
// Крок 2: Отримуємо співпадіння
let matches = regexp.matches(
in: markdown, options: [],
range: NSRange(location: 0, length: markdown.count)
)
// Крок 3: Кожному співпадінню ставимо у відповідність екземпляр структури Link
return matches.compactMap { match in
return Link(markdown: markdown, match: match)
}
}
}
Прикольні приклади з практики
Картки в Grammarly Keyboard
Певний час тому в нашій роботі над Grammarly Keyboard постала необхідність показувати картки з виправленнями тексту. Формат, у якому приходили дані до таких виправлень, був різновидом HTML, і був в першу чергу адаптованим для використання у вебсторінках. Однак, нам треба було показувати нативні картки, тому ці повідомлення слід було якось розпарсити. Ось такий вигляд мали картки та формат даних для них:
 | <span class='gr_grammar_ins'>the</span> owner<span class='gr_grammar_ins'>an</span> owner |
 | Dr. <span class='gr_grammar_del'>Dr.</span> |
 | looks <span class='gr_grammar_del'>as</span>→looks <span class='gr_grammar_ins'>like</span> |
 | <span class='gr_grammar_del'>gotta</span>→<span class='gr_grammar_ins'>has got to</span><span class='gr_grammar_del'>gotta</span>→<span class='gr_grammar_ins'>has to</span><span class='gr_grammar_del'>gotta</span>→<span class='gr_grammar_ins'>must</span>` |
Використовувати WebKit - занадто дорого для такої задачі, особливо в контексті AppExtension, яким є наша кастомна мобільна клавіатура. Значно простіше розпарсити такий формат за допомогою не дуже складної регулярки, наприклад, такої:
([^<]*)<span\s+class='gr_grammar_(ins|del)'>([^<]*)<\/span>([^<→]*)(→)?
Тести до State Machine
У своїй практиці я доволі часто користуюсь таким патерном як Стейт-Машина. Наприклад, ось такою:
class StateMachine {
enum State: String, Equatable, CaseIterable {
case none
case loading
case cancelling
case error
case empty
case data
}
enum Event: String, Equatable, CaseIterable {
case loadStarted
case cancelStarted
case cancelFinished
case loadFailed
case loadFinishedWithData
case loadFinishedWithNoData
}
var state: State = .none {
didSet {
guard oldValue != state else { return }
}
}
func transition(with event: Event) {
switch (state, event) {
case (.none, .loadStarted):
state = .loading
case (.none, _):
break
case (.loading, .cancelStarted):
state = .cancelling
case (.loading, .loadFailed):
state = .error
case (.loading, .loadFinishedWithNoData):
state = .empty
case (.loading, .loadFinishedWithData):
state = .data
case (.loading, _):
break
case (.cancelling, .cancelFinished):
state = .none
case (.cancelling, _):
break
case (.error, .loadStarted):
state = .loading
case (.error, _):
break
case (.empty, .loadStarted):
state = .loading
case (.empty, _):
break
case (.data, .loadStarted):
state = .loading
case (.data, _):
break
}
}
}
Стейт-машина з прикладу вище моделює процес завантаження списку з якимось даними. Завантаження може бути скасоване користувачем, а також завершитись помилкою. Стейт-машини дозволяють легко виокремити чисту бізнес-логіку в окремий компонент, а бізнес-логіку слід покривати тестами та документувати в першу чергу. Існує багато способів покрити тестами стейт-машину, і зараз мова піде про досить незвичний. Ідея така: тест – це підпрограма, котра перевіряє, що компонент працює саме так, як ми задумали. Власне, опис того, як ми задумали – це документація. Тоді чому би в якості тесту не перевіряти, що стейт-машина працює так, як записано в документації? Заодно це допоможе підтримувати документацію актуальною.
Ми пишемо документацію у файлах .markdown, що знаходяться десь поряд з кодом. Багато інструментів перегляду Markdown підтримують діаграми у форматі Mermaid. Для нашої StateMachine, документація має приблизно такий вигляд:
State machine models the data loading process for ....
```mermaid
graph LR
none --loadStarted--> loading
loading --cancelStarted--> cancelling
loading --loadFailed--> error
loading --loadFinishedWithData--> data
loading --loadFinishedWithNoData--> empty
cancelling --cancelFinished--> none
error --loadStarted--> loading
empty --loadStarted--> loading
data --loadStarted--> loading
```
При перегляді діаграма автоматично компілюється у відповідне зображення:
Діаграми у форматі Mermaid нескладно розпарсити. Оскільки регулярні вирази не підтримують рекурсії, для цього потрібно буде два регулярних вирази: один, щоб знайти діаграму в тексті, і другий, щоб розбити діаграму на частинки, типу state --event--> newState.
Давайте представимо документацію стейт-машини у вигляді наступної структури:
struct StateMachineDocumentation {
struct TransitionDocumentation {
var stateFrom: String
var transition: String
var stateTo: String
}
var transitions: [TransitionDocumentation]
}
Аналогічно до прикладів вище, нескладно розпарсити документацію окремого перехoду типу state --event--> newState:
extension StateMachineDocumentation.TransitionDocumentation {
static private let transitionRegexp = try! NSRegularExpression(
pattern: #"^(\S*)\s*--\s*(\S*)-->\s*(\S*)$"#,
options: [.anchorsMatchLines]
)
static func parse(from document: String, range: NSRange) -> [StateMachineDocumentation.TransitionDocumentation] {
let matches = transitionRegexp.matches(
in: document, options: [],
range: range
)
return matches.compactMap { StateMachineDocumentation.TransitionDocumentation(document: document, match: $0) }
}
init?(document: String, match: NSTextCheckingResult) {
guard
match.numberOfRanges == 4,
let stateFrom = document.substring(nsRange: match.range(at: 1)),
let transition = document.substring(nsRange: match.range(at: 2)),
let stateTo = document.substring(nsRange: match.range(at: 3))
else {
return nil
}
self.stateFrom = String(stateFrom)
self.transition = String(transition)
self.stateTo = String(stateTo)
}
}
Також, користуючись регулярними виразами, у документації в форматі Markdown нескладно знайти фрагменти з діаграмами у форматі Mermaid:
extension StateMachineDocumentation {
static let mermaidRegexp = try! NSRegularExpression(
pattern: #"```mermaid(.|\n)*```"#,
options: []
)
static func parseDocumentations(from document: String) -> [StateMachineDocumentation] {
let matches = mermaidRegexp.matches(
in: document, options: [],
range: NSRange(location: 0, length: document.count)
)
return matches.map { .init(document: document, match: $0) }
}
init(document: String, match: NSTextCheckingResult) {
self.transitions = TransitionDocumentation.parse(from: document, range: match.range)
}
}
Тепер, коли ми вміємо парсити документацію стейт-машин, час написати тест, що перевіряє стейт-машину на відповідність документації:
func testStateMachineTransitions() {
// GIVEN
let stateMachine = StateMachine()
let stateMachineDoc = StateMachineDocumentation.parseDocumentations(
from: someDocWithMermaid
).first!
for transitionDoc in stateMachineDoc.transitions {
guard let stateFrom = StateMachine.State(rawValue: transitionDoc.stateFrom),
let transition = StateMachine.Event(rawValue: transitionDoc.transition),
let stateTo = StateMachine.State(rawValue: transitionDoc.stateTo) else {
continue
}
stateMachine.state = stateFrom
// WHEN
stateMachine.transition(with: transition)
// THEN
assert(stateMachine.state == stateTo)
}
}
Зверніть увагу, що формат документації не прив’язаний до конкретної стейт-машини, тому ми можемо писати тести на нові стейт-машини не змінюючи код, що парсить документацію. Головне, стани та переходи у стейт-машинах описувались рядком.
Поекспериментувати із прикладами вище можна, скачавши Playground.
Ітогі падвєдьом…
Перш за все, варто пригадати свій перший досвід створення парсера якихось даних у більш-менш складному текстовому форматі. Як правило, не можна отак взяти та в кілька лінійних рядочків коду написати парсер: у коді дуже швидко з’являються розгалуження, цикли, код стає складним, ми згадуємо способи спрощення цього коду з ООП чи ФП, довго дебажимо його, і в результаті закінчуємо роботу над ним із запізненням. Тому другий досвід створення парсера у нас починається з думок “а нам точно треба це робити?”, “а може є якась готова бібліотека для цього?”.
Після опанування регулярних виразів у Swift, задача “створити парсер” для вас у багатьох випадках стане дешевою: всю складну і нелінійну частину коду можемо перекласти на регулярки, залишаючи у Swift простий та лінійний алгоритм:
- Застосувати регулярку до тесту.
- Замапити відповідні частинки співпаддіння на нашу структуру.
Варто розуміти, що регулярні вирази не є срібною кулею, і не варто їх пхати всюди, де потрібно й де не потрібно. Однак, існує лише один надійний спосіб навчитись писати регулярки: писати багато регулярок. А тому пхайте їх усюди, де потрібно і де не потрібно, допоки у вас не з’явиться інтуїція у їх застосуванні.
Головне обмеження, про яке слід пам’ятати: регулярки не підтримують рекурсію. Тому якщо у форматі є вкладення, його не можливо розпарсити за допомогою єдиного регулярного виразу. Кожен рівень вкладення слід парсити окремою регуляркою. Саме тому для прикладу з діаграмою у форматі Mermaid довелось використовувати 2 регулярні вирази: один виокремлює діаграми у тексті, інший – переходи у діаграмах.
Створення регулярних виразів – це іноді тяжка операція, тому варто виносити їх у статичні (ліниві за замовчанням) константи. Втім, разом із тим, створення регулярних виразів також може завершитись помилкою. Ви могли помітити примусові оператори try! у прикладах вище. Щоб не допустити проблем в реальних програмах, коректність створення регулярних виразів варто покривати тестами. Коректність же самих регулярних виразів можна перевіряти модульними тестами прямо у regex101.com, для цього потрібно лише залогінитись.
Що далі?
Якщо тема вам зайшла на стільки, що ви хочете копнути глибоких глибин – тоді раджу книгу Jeffrey E.F. Friedl “Mastering Regullar Expressions”.
Якщо вам взагалі цікава тема створення парсерів, варто ознайомитись із Розширеними Формами Бекуса-Наура (РБНФ). Це науковий підхід описання синтаксису будь-якої мови програмування. Застосування його дуже сильно спрощує написання парсерів. Власне, якщо ви читали оригінальну книгу про Swift, то там є 2 великих розділи: той, що читають усі, та той, що читають люди, котрі пишуть компілятор. Останній документує формальну граматику мови Swift за допомогою РБНФ.
Якщо ж у вас є цікавий досвід з розробкою під iOS/macOS/watchOS/tvOS, і ви прагнете їм поділитись – пишіть мені на пошту: killobatt@gmail.com. Якщо не прагнете ділитись досвідом – то прагніть. А якщо ви ще не маєте досвіду – то здобувайте його разом із нами. Адже ми тут говоримо про Swift. Українською.